
Information Technology for Management
UNIT 1
The Five Generations of Computers
The history of computer development is often referred to in reference to the different generations of computing devices. Each of the five generations of computers is characterized by a major technological development that fundamentally changed the way computers operate, resulting in increasingly smaller, cheaper, more powerful and more efficient and reliable devices.
Here you'll learn about each of the five generations of computers and the technology developments that have led to the current devices that we use today.
First Generation (1940-1956) Vacuum Tubes
The first computers used vacuum tubes for circuitry and magnetic drums for memory, and were often enormous, taking up entire rooms. They were very expensive to operate and in addition to using a great deal of electricity, generated a lot of heat, which was often the cause of malfunctions.
First generation computers relied on machine language, the lowest-level programming language understood by computers, to perform operations, and they could only solve one problem at a time. Input was based on punched cards and paper tape, and output was displayed on printouts.
The UNIVAC and ENIAC computers are examples of first-generation computing devices. The UNIVAC was the first commercial computer delivered to a business client, the U.S. Census Bureau in 1951.
Second Generation (1956-1963) Transistors
Transistors replaced vacuum tubes and ushered in the second generation of computers. The transistor was invented in 1947 but did not see widespread use in computers until the late 1950s. The transistor was far superior to the vacuum tube, allowing computers to become smaller, faster, cheaper, more energy-efficient and more reliable than their first-generation predecessors. Though the transistor still generated a great deal of heat that subjected the computer to damage, it was a vast improvement over the vacuum tube. Second-generation computers still relied on punched cards for input and printouts for output.
Second-generation computers moved from cryptic binary machine language to symbolic, or assembly, languages, which allowed programmers to specify instructions in words. High-level programming languages were also being developed at this time, such as early versions of COBOL and FORTRAN. These were also the first computers that stored their instructions in their memory, which moved from a magnetic drum to magnetic core technology.
The first computers of this generation were developed for the atomic energy industry.
Third Generation (1964-1971) Integrated Circuits
The development of the integrated circuit was the hallmark of the third generation of computers. Transistors were miniaturized and placed on silicon chips, called semiconductors, which drastically increased the speed and efficiency of computers.
Instead of punched cards and printouts, users interacted with third generation computers through keyboards and monitorsand interfaced with an operating system, which allowed the device to run many different applications at one time with a central program that monitored the memory. Computers for the first time became accessible to a mass audience because they were smaller and cheaper than their predecessors.
Fourth Generation (1971-Present) Microprocessors
The microprocessor brought the fourth generation of computers, as thousands of integrated circuits were built onto a single silicon chip. What in the first generation filled an entire room could now fit in the palm of the hand. The Intel 4004 chip, developed in 1971, located all the components of the computer—from the central processing unit and memory to input/output controls—on a single chip.
In 1981 IBM introduced its first computer for the home user, and in 1984 Apple introduced the Macintosh. Microprocessors also moved out of the realm of desktop computers and into many areas of life as more and more everyday products began to use microprocessors.
As these small computers became more powerful, they could be linked together to form networks, which eventually led to the development of the Internet. Fourth generation computers also saw the development of GUIs, the mouse and handhelddevices.
Fifth Generation (Present and Beyond) Artificial Intelligence
Fifth generation computing devices, based on artificial intelligence, are still in development, though there are some applications, such as voice recognition, that are being used today. The use of parallel processing and superconductors is helping to make artificial intelligence a reality. Quantum computation and molecular and nanotechnology will radically change the face of computers in years to come. The goal of fifth-generation computing is to develop devices that respond to natural language input and are capable of learning and self-organization.
DID YOU KNOW...?
An integrated circuit (IC) is a small electronic device made out of a semiconductor material. The first integrated circuit was developed in the 1950s by Jack Kilby of Texas Instruments and Robert Noyce of Fairchild Semiconductor.
IT, as defined in this chapter, reflects the combination of three key technologies: digital computing, data storage, and the ability to transmit digital signals through telecommunications networks. Rapid changes in semiconductor technology, information storage, and networking, combined with advances in software, have enabled new applications, cost reductions, and the widespread diffusion of IT. The expanding array of applications makes IT more useful and further fuels the expansion of IT.
Semiconductor Technology
Enormous improvements in the performance of integrated circuits and cost reductions brought about by rapid miniaturization have driven much of the advances in IT. See sidebar, "Moore's Law."
A related trend is the migration of computing into other devices and equipment. This is not a new trend—automobiles have been major users of microprocessors since the late 1970s—but as semiconductor chips become more powerful and less expensive, they are becoming increasingly ubiquitous. Also, new capabilities are being added to chips. These include microelectromechanical systems (MEMs), such as sensors and actuators, and digital signal processors that enable cost reductions and extend IT into new types of devices. Examples of MEM devices include ink-jet printer cartridges, hard disk drive heads, accelerometers that deploy car airbags, and chemical and environmental sensors (Gulliksen 2000). Trends toward improvements in microelectronics and MEMs are expected to continue. See sidebar, "Nanoscale Electronics."
Information Storage
Disk drives and other forms of information storage reflect similar improvements in cost and performance. As a consequence, the amount of information in digital form has expanded greatly. Estimates of the amount of original information (excluding copies and reproductions) suggest that information on disk drives now constitutes the majority of information (Lyman and Varian 2000). Increasingly, much of this information is available on-line.
Computers, reflecting the improvements in their components, have shown similar dramatic improvements in performance. Due to improvements in semiconductors, storage, and other components, price declines in computers (adjusted for quality) have actually accelerated since 1995.
Networking
The third trend is the growth of networks. Computers are increasingly connected in networks, including local area networks and wide area networks. Many early commercial computer networks, such as those used by automated teller machines and airline reservation systems, used proprietary systems that required specialized software or hardware (or both). Increasingly, organizations are using open-standard, Internet-based systems for networks.As people have been able to interconnect and share information with each other, the value of IT has increased. See sidebar "Metcalfe's Law."
The growth in networking has been enabled by rapid advances in optical networking. In 1990, a single optical fiber could transmit about 1 billion bits per second; by 2000, a single fiber could transmit nearly 1 trillion bits per second (Optoelectronics Industry Development Association 2001).
The growth in networking is best illustrated by the rapid growth of the Internet. Worldwide, there were nearly 100 million Internet hosts—computers connected to the Internet—in July 2000, up from about 30 million at the beginning of 1998. Networking is evolving in several ways: more people and devices are becoming connected to the network, the speed and capacity of connections are increasing, and more people are obtaining wireless connections. See sidebar, "Wireless Networking."
Applications of IT
A fourth trend is the ever-increasing array of applications that make IT more useful. Computers were originally used primarily for data processing. As they became more powerful and convenient, applications expanded. Word processing, spreadsheets, and database programs were among the early minicomputer and PC applications. Over the past two decades, innovations in software have enabled applications to expand to include educational software, desktop publishing, computer-aided design and manufacturing, games, modeling and simulation, networking and communications software, electronic mail, the World Wide Web, digital imaging and photography, audio and video applications, electronic commerce applications, groupware, file sharing, search engines, and many others. The growth and diversity of applications greatly increase the utility of IT, leading to its further expansion.
In the 1960s, computers were used primarily in the R&D community and in the offices of large companies and agencies. Over the past few decades, the expansion of applications has contributed to the rapid diffusion of IT to affect nearly everyone, not just the relatively few people in computer-intensive jobs. IT has become common in schools, libraries, homes, offices, and businesses. For example, corner grocery stores use IT for a variety of electronic transactions such as debit and credit payments, and automobile repair shops use IT to diagnose problems and search for parts from dealers. New IT applications are still developing rapidly; for example, instant messaging and peer-to-peer communication systems such as Napster are examples that have become popular in the past 2 years. See sidebar, "Peer-to-Peer Applications."
Major Technological Developments and Trends
General Developments and trends
- The cost-performance advantage of computers over manual labor will increase.
- Graphical and other user-friendly interfaces will dominate PCs.
- Storage Capacity will increase dramatically.
- Data warehouses will store ever-increasing amounts of information.
- Multimedia use, including virtual reality, will increase significantly.
- Intelligent systems, especially artificial neural computing and expert systems, will increase in importance and be embedded in other systems
- The use of intelligent agents will make computers "smarter".
- There is a push for open architecture (e.g. the use of web services and Linux).
- Object-oriented programming and document management will be widely accepted.
- Artificial Intelligence systems are moving to learning-management systems.
- Computers will be increasingly compact and more portable.
- Limited capability computers are available for less than $100.
- There is proliferation of embedded technologies (especially intelligent ones).
- The use of plug-and-play software will increase (software-as-a-service, utility computing).
Networking Computing Developments and Trends
- Optical computing will increase network capacity and speed, facilitating the use of the home Internet.
- Storage networks will be popular.
- Mobile and wireless applications will become a major component of IT.
- Home computing will be integrated with the telephone, television and other electronic services to create smart home appliances.
- The use of the internet will grow, and it will change the way we live,work, and learn.
- Corporate portals will connect companies with their employees, business partners, and the public.
- Intranets will be the dominating network systems in most organizations.
- E-commerce over the internet will grow rapidly, changing the manner in which business is conducted.
- Intelligent software agents will roam through databases and networks, conducting time-consuming tasks for their masters.
- Interpersonal transmission will grow (one-to-one, one-to-many, many-to-many).
- More transactions among organizations will be conducted electronically, in what is called business-to-business(B2B) commerce.
- Networks and Intelligent systems will be major contributors toward improved national security and counter terrorism efforts.
- RFID (Radio Frequency Identification) will change supply chains and retailing.
Managerial Issues :
- Recognizing opportunities for using IT and Web-based systems for strategic advantage
- Who will build, operate, and maintain the information systems?
- How much IT?
- How important is IT?
- Is the situation going to change?
- Globalization.
- Ethics and social Issues.
- Transforming the organization to the digital economy.
IT Planning
A good IT planning process can help ensure that IT aligns, and stays aligned, with an organization.Because, organizational goals change over time, it is not sufficient to develop a long-term IT strategy and not reexamine the strategy on a regular basis.For this reason, IT planning is not a one shot process.
IT planning is the organized planning of IT infrastructure and applications portfolios done at various levels of the organization.It is important to both the planners and end users.
Typically, annual planning cycles are established to identify potentially beneficial IT services, to perform cost-benefit analyses, and to subject the list of potential projects to resource allocation analysis.Often the entire process is conducted by an IT steering committee.
IT Steering Committee
IT planning is the organized planning of IT infrastructure and applications portfolios done at various levels of the organization.It is important to both the planners and end users.
Typically, annual planning cycles are established to identify potentially beneficial IT services, to perform cost-benefit analyses, and to subject the list of potential projects to resource allocation analysis.Often the entire process is conducted by an IT steering committee.
IT Steering Committee
- The committee's major tasks are:
- Direction Setting
- Rationing
- Structuring
- Staffing
- Communication
- Evaluation

Nolan’s Stages of IS Growth
- Initiation
- Expansion
- Control
- Integration
- Data administration
- Maturity


Scenario Planning is a methodology in which planners first create several scenarios, then a team complies as many future events as possible that may influence the outcome of each scenarios
Five reasons to do scenario planning are:
- to ensure that you are no focusing on catastrophe to the exclusion of opportunity
- to help you allocate resources more prudently
- to preserve your options
- to ensure that you are not still "fighting the last war"
- to give you the opportunity to rehearse testing and training of people to go through the process.
A major aspect of IT planning is allocating an organization's IT resources to the right set of projects.
Resource allocation consists of developing the hardware,software,data communications and networks,facilities,personnel, and financial plans needed to execute the master development plan as defined in the requirements analysis.
IT Infrastructure Considerations
- Reach
- Range

- Powerful competitive advantage
- Importance
- Organizing for effective planning
- Fitting the IT architecture to the organization
- IT architecture planning
- IT policy
- Ethical and legal issuesateg
- IT strategy
- Be a leader in technology
- Be a follower
- Be an experimenter, on a small scale
Role of IT in Management
Operational Activities
Operational activities deal with the day-to-day operations of an organization, such as assigning employees to tasks and recording the number of hours they work, or placing a purchase order.Operational activities are the short-term in nature.The information systems that support them are mainly TPSs, MISs and mobile systems.Operational systems are used mostly by supervisors(first-line managers), operators, and clerical employees.
Managerial Activities
These are also called tactical activities or decisions, deal in general with middle-management activities such as short term planning, organizing and control. Computerized managerial systems are frequently equated with MISs, because MISs are designed to summarize data and prepare reports.Middle Managers also can get quick answers to queries from such systems ans the need for answers arises, using BI reporting and query capabilities.
Strategic activities
These are activities or decisions that deal with situations that may significantly change the manner in which business is done.Traditionally, strategic activities involved only long-range planning.Introducing a new product-line,expanding the business by acquiring supporting businesses, and moving operations to a foreign country, are prime examples of long-range activities.A long-range planning document traditionally outlines strategies and plans for the next five or even 10 years.From this plan, companies derive their short-range planning budgeting and resource allocation.Strategic activities help organizations in two ways
First,strategic response activities can react quickly to a major competitor's action or to any other significant change in the enterprise's environment.
Second, instead of waiting for a competitor to introduce a major change or innovation, an organization can be the initiator of change.
Choice Phase:
Database Management: The foundation of data management has 4 building blocks:
Data problems:
Incorrect data,Redundant Data,Stolen data,Irrelavant data and Misssing data
Data is bits and bytes.
A logical grouping of characters into a word , a group of words,or a complete number is a field.
A logical group of related fields such as customers name,product sold and hours worked are examples of Record.
A logical group of related records is called a file.
Files are of different types:
Type 1:
Master Files-Permanent data
Transaction files- Temporary data
Type 2:
Sequential Files
Indexed Files
Relative files
Files organization is of 3 types:
Sequential Organization
Direct or Random file Organization
Indexed sequential Organization.
Problems in File Management:
Database is an organized logical grouping of related files.In a database, data are integrated and related so that one set of software programs provides access to all the data, alleviating many of the problems associated with data file environments.Therefore, data redundancy,data isolation, and inconsistency are minimized.
Types of databases
Centralized database- has all the related files in one physical location.
Distributed database- has complete copies of a databases, or portions of a database, in more than one location, which is usually, close to the user.There are two types of distributed databases:replicated and partitioned.
Advantages and Capabilities of a DBMS:
DBMS contains 4 major components:
The data model-hierarchical,network,relational object oriented,object relational,hypermedia, and multidimensional models
The DDL - is the language is used by programmers to specify the types of information and structure of database.
The DML - is used with a third or fourth generation language to manipulate the data in the database.This language contains commands that permit end users and programming specialists to extract data from database to satisfy information requests and develop applications.
The Data Dictionary - stores definitions of data elements and data characteristics such as usage, physical representation, ownership,authorization and security.
DBMS Benifits:
Entity Relationship Diagrams
Overview
The need of Normalization
one simple E-R model database.
In first look the above table is looking so arranged and well in format but if we try to find out what exactly this table is saying to us , we can easily figure out the various anomalies in this table . Ok let me help you guys in finding out the same.
Table shown above Student Details ,Course Details and Result Details can be further divided. Student Details attribute is divided into Student#(Student Number) , Student Name and date of birth. Course Details is divided into Course# ,Course Name,Prerequisites and duration. Similarly Results attribute is divided into DateOfexam,Marks and Grade.
Let us re-visit 1NF table structure.
COURSE TABLE
RESULT TABLE
EXAM DATE Table
We already concluded that :
Assume, at present, as per the university evaluation policy,
The University management which is committed to improve the quality of education ,wants to change the existing grading system to a new grading system .In the present RESULT table structure ,
After Normalizing tables to 3NF , we got rid of all the anomalies and inconsistencies. Now we can add new grade systems, update the existing one and delete the unwanted ones.
Hence the Third Normal form is the most optimal normal form and 99% of the databases which require efficiency in
Operational Activities
Operational activities deal with the day-to-day operations of an organization, such as assigning employees to tasks and recording the number of hours they work, or placing a purchase order.Operational activities are the short-term in nature.The information systems that support them are mainly TPSs, MISs and mobile systems.Operational systems are used mostly by supervisors(first-line managers), operators, and clerical employees.
Managerial Activities
These are also called tactical activities or decisions, deal in general with middle-management activities such as short term planning, organizing and control. Computerized managerial systems are frequently equated with MISs, because MISs are designed to summarize data and prepare reports.Middle Managers also can get quick answers to queries from such systems ans the need for answers arises, using BI reporting and query capabilities.
Strategic activities
These are activities or decisions that deal with situations that may significantly change the manner in which business is done.Traditionally, strategic activities involved only long-range planning.Introducing a new product-line,expanding the business by acquiring supporting businesses, and moving operations to a foreign country, are prime examples of long-range activities.A long-range planning document traditionally outlines strategies and plans for the next five or even 10 years.From this plan, companies derive their short-range planning budgeting and resource allocation.Strategic activities help organizations in two ways
First,strategic response activities can react quickly to a major competitor's action or to any other significant change in the enterprise's environment.
Second, instead of waiting for a competitor to introduce a major change or innovation, an organization can be the initiator of change.
Decision-making, in organizations, is regarded as a rational process Herbert A. Simon has given a model to describe the decision–making process. The model comprises of three major phases, namely.
i) Intelligence
ii) Design, and
iii) Choice
Intelligence Phase:
In this phase, the decision maker scans the environment & identifies the problem or opportunity. The scanning of environment may be continuous or non-continuous. Intelligence phase of decision-making process involves:
a. Problem Searching
b. Problem Formulation
Problem Searching: For searching the problem, the reality or actual is compared to some standards. Differences are measured & the differences are evaluated to determine whether there is any problem or not.
Problem Formulation: When the problem is identified, there is always a risk of solving the wrong problem. In problem formulation, establishing relations with some problem solved earlier or an analogy proves quite useful.
Design Phase:
In this phase, the decision maker identifies alternative courses of action to solve the problem. Inventing or developing of various alternatives is time consuming and crucial activity, as the decision maker has to explore all the possible alternatives.
Choice Phase:
At this stage, one of the alternatives developed in design phase is selected & is called a decision. For selecting an alternative, detailed analysis of each and every alternative is made. Having made the decision, it is implemented. The decision maker in choice phase may reject all the alternatives and return to the design phase for developing more alternatives.
UNIT III
Database Management: The foundation of data management has 4 building blocks:
- Data Profiling - Understanding the data
- Data quality management -improving the quantity of data
- Data Integration-combining similar data from multiple sources
- Data augmentation- improving the value of the data
Data problems:
Incorrect data,Redundant Data,Stolen data,Irrelavant data and Misssing data
- the amount of data increases exponentially with time
- data are scattered throughout the organizations
- An ever-increasing amount of external data
- data security,quality, and integrity are critical,yet are easily jeopardized
- data management tool selection
- No quality control checks
- redundant data and huge maintenance problems
Structure of a File:
File-------->Records-------->Fields--------->DataData is bits and bytes.
A logical grouping of characters into a word , a group of words,or a complete number is a field.
A logical group of related fields such as customers name,product sold and hours worked are examples of Record.
A logical group of related records is called a file.
Files are of different types:
Type 1:
Master Files-Permanent data
Transaction files- Temporary data
Type 2:
Sequential Files
Indexed Files
Relative files
Files organization is of 3 types:
Sequential Organization
Direct or Random file Organization
Indexed sequential Organization.
Problems in File Management:
- Data Redundancy- duplication
- Data inconsistency- values across copies doesn't synchronize
- Data Isolation-stored in different formats eg: inches vs cms
- Data integrity-constraints
Database is an organized logical grouping of related files.In a database, data are integrated and related so that one set of software programs provides access to all the data, alleviating many of the problems associated with data file environments.Therefore, data redundancy,data isolation, and inconsistency are minimized.
DBMS = Data + Programs that manipulate the data
Types of databases
Centralized database- has all the related files in one physical location.
Distributed database- has complete copies of a databases, or portions of a database, in more than one location, which is usually, close to the user.There are two types of distributed databases:replicated and partitioned.
Advantages and Capabilities of a DBMS:
- Persistence
- Query ability
- Concurrency
- Backup and replication
- Rule Enforcement
- Security
- Computation
- Change and access logging
- Automated Optimization
- Physical View deals with the actual physical arrangement and location of data in the direct access storage devices(DASDs)
- Logical View or user's view of a database program represents data in a format that is meaningful to a user and to the software programs that process those data.
DBMS contains 4 major components:
The data model-hierarchical,network,relational object oriented,object relational,hypermedia, and multidimensional models
The DDL - is the language is used by programmers to specify the types of information and structure of database.
The DML - is used with a third or fourth generation language to manipulate the data in the database.This language contains commands that permit end users and programming specialists to extract data from database to satisfy information requests and develop applications.
The Data Dictionary - stores definitions of data elements and data characteristics such as usage, physical representation, ownership,authorization and security.
DBMS Benifits:
- Improved strategic use of corporate data
- Reduced complexity of the organization's information systems environment
- Reduced data redundancy and inconsistency
- Enhanced data integrity
- Application - data independence
- Improved Security
- Reduced application development and maintenance costs
- Improved flexibility of information systems
- Increased access and availability of data and information
Entity Relationship Diagrams
Overview
An ER model is an abstract way to describe a database. Describing a database usually starts with a relational database, which stores data in tables. Some of the data in these tables point to data in other tables - for instance, your entry in the database could point to several entries for each of the phone numbers that are yours. The ER model would say that you are an entity, and each phone number is an entity, and the relationship between you and the phone numbers is 'has a phone number'. Diagrams created to design these entities and relationships are called entity–relationship diagrams or ER diagrams.
Using the three schema approach to software engineering, there are three levels of ER models that may be developed.
- The conceptual data model: This is the highest level ER model in that it contains the least granular detail but establishes the overall scope of what is to be included within the model set. The conceptual ER model normally defines master reference data entities that are commonly used by the organization. Developing an enterprise-wide conceptual ER model is useful to support documenting the data architecture for an organization.
A conceptual ER model may be used as the foundation for one or more logical data models. The purpose of the conceptual ER model is then to establish structural metadata commonality for the master data entities between the set of logical ER models. The conceptual data model may be used to form commonality relationships between ER models as a basis for data model integration. - The logical data model: A logical ER model does not require a conceptual ER model especially if the scope of the logical ER model is to develop a single disparate information system. The logical ER model contains more detail than the conceptual ER model. In addition to master data entities, operational and transactional data entities are now defined. The details of each data entity are developed and the entity relationships between these data entities are established. The logical ER model is however developed independent of technology into which it will be implemented.
- The physical model: One or more physical ER models may be developed from each logical ER model. The physical ER model is normally developed to be instantiated as a database. Therefore, each physical ER model must contain enough detail to produce a database and each physical ER model is technology dependent since each database management system is somewhat different.
The physical model is normally forward engineered to instantiate the structural metadata into a database management system as relational database objects such as database tables,database indexes such as unique key indexes, and database constraints such as a foreign key constraint or a commonality constraint. The ER model is also normally used to design modifications to the relational database objects and to maintain the structural metadata of the database.
The first stage of information system design uses these models during the requirements analysis to describe information needs or the type of information that is to be stored in a database. Thedata modeling technique can be used to describe any ontology (i.e. an overview and classifications of used terms and their relationships) for a certain area of interest. In the case of the design of an information system that is based on a database, the conceptual data model is, at a later stage (usually called logical design), mapped to a logical data model, such as the relational model; this in turn is mapped to a physical model during physical design. Note that sometimes, both of these phases are referred to as "physical design".
Entity–relationship modelling
[edit]The building blocks: entities, relationships, and attributes


An entity may be defined as a thing which is recognized as being capable of an independent existence and which can be uniquely identified. An entity is an abstraction from the complexities of a domain. When we speak of an entity, we normally speak of some aspect of the real world which can be distinguished from other aspects of the real world.[4]
An entity may be a physical object such as a house or a car, an event such as a house sale or a car service, or a concept such as a customer transaction or order. Although the term entity is the one most commonly used, following Chen we should really distinguish between an entity and an entity-type. An entity-type is a category. An entity, strictly speaking, is an instance of a given entity-type. There are usually many instances of an entity-type. Because the term entity-type is somewhat cumbersome, most people tend to use the term entity as a synonym for this term.
Entities can be thought of as nouns. Examples: a computer, an employee, a song, a mathematical theorem.
A relationship captures how entities are related to one another. Relationships can be thought of as verbs, linking two or more nouns. Examples: an ownsrelationship between a company and a computer, a supervises relationship between an employee and a department, a performs relationship between an artist and a song, a proved relationship between a mathematician and a theorem.
The model's linguistic aspect described above is utilized in the declarative database query language ERROL, which mimics natural language constructs. ERROL's semantics and implementation are based on Reshaped relational algebra (RRA), a relational algebra which is adapted to the entity–relationship model and captures its linguistic aspect.
Entities and relationships can both have attributes. Examples: an employee entity might have a Social Security Number (SSN) attribute; the proved relationship may have adate attribute.
Every entity (unless it is a weak entity) must have a minimal set of uniquely identifying attributes, which is called the entity's primary key.
Entity–relationship diagrams don't show single entities or single instances of relations. Rather, they show entity sets and relationship sets. Example: a particular song is an entity. The collection of all songs in a database is an entity set. The eaten relationship between a child and her lunch is a single relationship. The set of all such child-lunch relationships in a database is a relationship set. In other words, a relationship set corresponds to a relation in mathematics, while a relationship corresponds to a member of the relation.
Certain cardinality constraints on relationship sets may be indicated as well.
What is Normalization?
Database designed based on ER model may have some amount of inconsistency, ambiguity and redundancy. To resolve these issues some amount of refinement is required. This refinement process is called as Normalization. I know all of you are clear with the definition, let’s go with :
Database designed based on ER model may have some amount of inconsistency, ambiguity and redundancy. To resolve these issues some amount of refinement is required. This refinement process is called as Normalization. I know all of you are clear with the definition, let’s go with :
- what is the need of normalization?
- What are the problems we can face if we proceed without normalization?
- What are the advantages of normalization?
The need of Normalization
one simple E-R model database.
| Student Details | Course Details | Result details |
| 1001 Ram 11/09/1986 | M4 Basic Maths 7 | 11/11/2004 89 A |
| 1002 Shyam 12/08/1987 | M4 Basic Maths 7 | 11/11/2004 78 B |
| 1001 Ram 23/06/1987 | H6 4 | 11/11/2004 87 A |
| 1003 Sita 16/07/1985 | C3 Basic Chemistry 11 | 11/11/2004 90 A |
| 1004 Gita 24/09/1988 | B3 8 | 11/11/2004 78 B |
| 1002 Shyam 23/06/1988 | P3 Basic Physics 13 | 11/11/2004 67 C |
| 1005 Sunita 14/09/1987 | P3 Basic Physics 13 | 11/11/2004 78 B |
| 1003 Sita 23/10/1987 | B4 5 | 11/11/2004 67 C |
| 1005 Sunita 13/03/1990 | H6 4 | 11/11/2004 56 D |
| 1004 Gita 21/08/1987 | M4 Basic Maths 7 | 11/11/2004 78 B |
In first look the above table is looking so arranged and well in format but if we try to find out what exactly this table is saying to us , we can easily figure out the various anomalies in this table . Ok let me help you guys in finding out the same.
- Insert Anomaly: We cannot insert prospective course which does not have any registered student or we cannot insert student details that is yet to register for any course.
- Update Anomaly: if we want to update the course M4’s name we need to do this operation three times. Similarly we may have to update student 1003’s name twice if it changes.
- Delete Anomaly: if we want to delete a course M4 , in addition to M4 occurs details , other critical details of student also will be deleted. This kind of deletion is harmful to business. Moreover, M4 appears thrice in above table and needs to be deleted thrice.
- Duplicate Data: Course M4’s data is stored thrice and student 1002’s data stored twice .This redundancy will increase as the number of course offerings increases.
Process of normalization:
Before getting to know the normalization techniques in detail, let us define a few building blocks which are used to define normal form.
Before getting to know the normalization techniques in detail, let us define a few building blocks which are used to define normal form.
- Determinant : Attribute X can be defined as determinant if it uniquely defines the value Y in a given relationship or entity .To qualify as determinant attribute need NOT be a key attribute .Usually dependency of attribute is represented as X->Y ,which means attribute X decides attribute Y.
Example: In RESULT relation, Marks attribute may decide the grade attribute .This is represented as Marks->grade and read as Marks decides Grade.
Marks -> Grade
In the result relation, Marks attribute is not a key attribute .Hence it can be concluded that key attributes are determinants but not all the determinants are key attributes.
Marks -> Grade
In the result relation, Marks attribute is not a key attribute .Hence it can be concluded that key attributes are determinants but not all the determinants are key attributes.
- Functional Dependency: Yes functional dependency has definition but let’s not care about that. Let’s try to understand the concept by example. Consider the following relation :
REPORT(Student#,Course#,CourseName,IName,Room#,Marks,Grade)
Where:
Where:
- Student#-Student Number
- Course#-Course Number
- CourseName -CourseName
- IName- Name of the instructor who delivered the course
- Room#-Room number which is assigned to respective instructor
- Marks- Scored in Course Course# by student Student #
- Grade –Obtained by student Student# in course Course #
- Student#,Course# together (called composite attribute) defines EXACTLY ONE value of marks .This can be symbolically represented as
Student#Course# Marks
This type of dependency is called functional dependency. In above example Marks is functionally dependent on Student#Course#.
Other Functional dependencies in above examples are:
This type of dependency is called functional dependency. In above example Marks is functionally dependent on Student#Course#.
Other Functional dependencies in above examples are:
- Course# -> CourseName
- Course#-> IName(Assuming one course is taught by one and only one instructor )
- IName -> Room# (Assuming each instructor has his /her own and non shared room)
- Marks ->Grade
Formally we can define functional dependency as: In a given relation R, X and Y are attributes. Attribute Y is functional dependent on attribute X if each value of X determines exactly one value of Y. This is represented as :
X->Y
However X may be composite in nature.
X->Y
However X may be composite in nature.
- Full functional dependency: In above example Marks is fully functional dependent on student#Course# and not on the sub set of Student#Course#.This means marks cannot be determined either by student # or Course# alone .It can be determined by using Student# and Course# together. Hence Marks is fully functional dependent on student#course#.
CourseName is not fully functionally dependent on student#course# because one of the subset course# determines the course name and Student# does not having role in deciding Course name .Hence CourseName is not fully functional dependent on student #Course#.
Student#
Marks
Course#
Formal Definition of full functional dependency : In a given relation R ,X and Y are attributes. Y is fully functionally dependent on attribute X only if it is not functionally dependent on sub-set of X.However X may be composite in nature.
Student#
Marks
Course#
Formal Definition of full functional dependency : In a given relation R ,X and Y are attributes. Y is fully functionally dependent on attribute X only if it is not functionally dependent on sub-set of X.However X may be composite in nature.
- Partial Dependency: In the above relationship CourseName,IName,Room# are partially dependent on composite attribute Student#Course# because Course# alone can defines the coursename, IName,Room#.
Room#
IName
CourseName
Course#
Student#
Formal Definition of Partial dependency: In a given relation R, X and Y are attributes .Attribute Y is partially dependent on the attribute X only if it is dependent on subset attribute X .However X may be composite in nature.
IName
CourseName
Course#
Student#
Formal Definition of Partial dependency: In a given relation R, X and Y are attributes .Attribute Y is partially dependent on the attribute X only if it is dependent on subset attribute X .However X may be composite in nature.
- Transitive Dependency: In above example , Room# depends on IName and in turn depends on Course# .Here Room# transitively depends on Course#.
IName
Room#
Course#
Similarly Grade depends on Marks,in turn Marks depends on Student#Course# hence Grade
Fully transitively depends on Student#Course#.
Room#
Course#
Similarly Grade depends on Marks,in turn Marks depends on Student#Course# hence Grade
Fully transitively depends on Student#Course#.
- Key attributes : In a given relationship R ,if the attribute X uniquely defines all other attributes ,then the attribute X is a key attribute which is nothing but the candidate key.
Ex: Student#Course# together is a composite key attribute which determines all attributes in relationship REPORT(student#,Course#,CourseName,IName,Room#,Marks,Grade)uniquely.Hence Student# and Course# are key attributes.
Types of Normal Forms
Types of Normal Forms
- First Normal Form(1NF)
A relation R is said to be in first normal form (1NF) if and only if all the attributes of the relation R are atomic in nature
| Student Details | Course Details | Result details |
| 1001 Ram 11/09/1986 | M4 Basic Maths 7 | 11/11/2004 89 A |
| 1002 Shyam 12/08/1987 | M4 Basic Maths 7 | 11/11/2004 78 B |
| 1001 Ram 23/06/1987 | H6 4 | 11/11/2004 87 A |
| 1003 Sita 16/07/1985 | C3 Basic Chemistry 11 | 11/11/2004 90 A |
| 1004 Gita 24/09/1988 | B3 8 | 11/11/2004 78 B |
| 1002 Shyam 23/06/1988 | P3 Basic Physics 13 | 11/11/2004 67 C |
| 1005 Sunita 14/09/1987 | P3 Basic Physics 13 | 11/11/2004 78 B |
| 1003 Sita 23/10/1987 | B4 5 | 11/11/2004 67 C |
| 1005 Sunita 13/03/1990 | H6 4 | 11/11/2004 56 D |
| 1004 Gita 21/08/1987 | M4 Basic Maths 7 | 11/11/2004 78 B |
Table shown above Student Details ,Course Details and Result Details can be further divided. Student Details attribute is divided into Student#(Student Number) , Student Name and date of birth. Course Details is divided into Course# ,Course Name,Prerequisites and duration. Similarly Results attribute is divided into DateOfexam,Marks and Grade.
- Second Normal Form (2NF)
A relation is said to be in Second Normal Form if and only If :
- It is in the first normal form ,and
- No partial dependency exists between non-key attributes and key attributes.
Let us re-visit 1NF table structure.
- Student# is key attribute for Student ,
- Course# is key attribute for Course
- Student#Course# together form the composite key attributes for result relationship.
- Other attributes are non-key attributes.
To make this table 2NF compliant, we have to remove all the partial dependencies.
- StudentName and DateOfBirth depends only on student#.
- CourseName,PreRequisite and DurationInDays depends only on Course#
- DateOfExam depends only on Course#.
To remove this partial dependency we need to split Student_Course_Result table into four separate tables ,STUDENT ,COURSE,RESULT and EXAM_DATE tables as shown in figure.
STUDENT TABLE
STUDENT TABLE
| Student # | Student Name | DateofBirth |
| 1001 | Ram | Some value |
| 1002 | Shyam | Some value |
| 1003 | Sita | Some value |
| 1004 | Geeta | Some value |
| 1005 | Sunita | Some value |
COURSE TABLE
| Course# | CourseName | Duration of days |
| C3 | Bio Chemistry | 3 |
| B3 | Botany | 8 |
| P3 | Nuclear Physics | 1 |
| M4 | Applied Mathematics | 4 |
| H6 | American History | 5 |
| B4 | Zoology | 9 |
RESULT TABLE
| Student# | Course# | Marks | Grade |
| 1001 | M4 | 89 | A |
| 1002 | M4 | 78 | B |
| 1001 | H6 | 87 | A |
| 1003 | C3 | 90 | A |
| 1004 | B3 | 78 | B |
| 1002 | P3 | 67 | C |
| 1005 | P3 | 78 | B |
| 1003 | B4 | 67 | C |
| 1005 | H6 | 56 | D |
| 1004 | M4 | 78 | B |
EXAM DATE Table
| Course# | DateOfExam |
| M4 | Some value |
| H6 | Some value |
| C3 | Some value |
| B3 | Some value |
| P3 | Some value |
| B4 | Some value |
- In the first table (STUDENT) ,the key attribute is Student# and all other non-key attributes, StudentName and DateOfBirth are fully functionally dependant on the key attribute.
- In the Second Table (COURSE) , Course# is the key attribute and all the non-key attributes, CourseName, DurationInDays are fully functional dependant on the key attribute.
- In third table (RESULT) Student#Course# together are key attributes and all other non key attributes, Marks and Grade are fully functional dependant on the key attributes.
- In the fourth Table (EXAM DATE) Course# is the key attribute and the non key attribute ,DateOfExam is fully functionally dependant on the key attribute.
At first look it appears like all our anomalies are taken away ! Now we are storing Student 1003 and M4 record only once. We can insert prospective students and courses at our will. We will update only once if we need to change any data in STUDENT,COURSE tables. We can get rid of any course or student details by deleting just one row.
Let us analyze the RESULT Table
Let us analyze the RESULT Table
| Student# | Course# | Marks | Grade |
| 1001 | M4 | 89 | A |
| 1002 | M4 | 78 | B |
| 1001 | H6 | 87 | A |
| 1003 | C3 | 90 | A |
| 1004 | B3 | 78 | B |
| 1002 | P3 | 67 | C |
| 1005 | P3 | 78 | B |
| 1003 | B4 | 67 | C |
| 1005 | H6 | 56 | D |
| 1004 | M4 | 78 | B |
We already concluded that :
- All attributes are atomic in nature
- No partial dependency exists between the key attributes and non-key attributes
- RESULT table is in 2NF
Assume, at present, as per the university evaluation policy,
- Students who score more than or equal to 80 marks are awarded with “A” grade
- Students who score more than or equal to 70 marks up till 79 are awarded with “B” grade
- Students who score more than or equal to 60 marks up till 69 are awarded with “C” grade
- Students who score more than or equal to 50 marks up till 59 are awarded with “D” grade
The University management which is committed to improve the quality of education ,wants to change the existing grading system to a new grading system .In the present RESULT table structure ,
- We don’t have an option to introduce new grades like A+ ,B- and E
- We need to do multiple updates on the existing record to bring them to new grading definition
- We will not be able to take away “D” grade if we want to.
- 2NF does not take care of all the anomalies and inconsistencies.
- Third Normal Form (3NF)
A relation R is said to be in 3NF if and only if
- It is in 2NF
- No transitive dependency exists between non-key attributes and key attributes.
In the above RESULT table Student# and Course# are the key attributes. All other attributes, except grade are non-partially , non – transitively dependant on key attributes. The grade attribute is dependant on “Marks “ and in turn “Marks” is dependent on Student#Course#. To bring the table in 3NF we need to take off this transitive dependency.
| Student# | Course# | Marks |
| 1001 | M4 | 89 |
| 1002 | M4 | 78 |
| 1001 | H6 | 87 |
| 1003 | C3 | 90 |
| 1004 | B3 | 78 |
| 1002 | P3 | 67 |
| 1005 | P3 | 78 |
| 1003 | B4 | 67 |
| 1005 | H6 | 56 |
| 1004 | M4 | 78 |
| UpperBound | LowerBound | Grade |
| 100 | 95 | A+ |
| 94 | 90 | A |
| 89 | 85 | B+ |
| 84 | 80 | B |
| 79 | 75 | B- |
| 74 | 70 | C |
| 69 | 65 | C- |
After Normalizing tables to 3NF , we got rid of all the anomalies and inconsistencies. Now we can add new grade systems, update the existing one and delete the unwanted ones.
Hence the Third Normal form is the most optimal normal form and 99% of the databases which require efficiency in
- INSERT
- UPDATE
- DELETE
Operations are designed in this normal form.
The main normal forms are summarized below.
| Normal form | Defined by | In | Brief definition | |
|---|---|---|---|---|
| 1NF | First normal form | Two versions: E.F. Codd(1970), C.J. Date (2003) | 1970 [1]and 2003[9] | Table faithfully represents a relation, primarily meaning it has at least one candidate key |
| 2NF | Second normal form | E.F. Codd | 1971 [2] | No non-prime attribute in the table is functionally dependent on a proper subset of any candidate key |
| 3NF | Third normal form | Two versions: E.F. Codd(1971), C. Zaniolo (1982) | 1971 [2]and 1982[10] | Every non-prime attribute is non-transitively dependent on every candidate key in the table. The attributes that do not contribute to the description of the primary key are removed from the table. In other words, no transitive dependency is allowed. |
| EKNF | Elementary Key Normal Form | C. Zaniolo | 1982 [10] | Every non-trivial functional dependency in the table is either the dependency of an elementary key attribute or a dependency on a superkey |
| BCNF | Boyce–Codd normal form | Raymond F. Boyce andE.F. Codd | 1974 [11] | Every non-trivial functional dependency in the table is a dependency on a superkey |
| 4NF | Fourth normal form | Ronald Fagin | 1977 [12] | Every non-trivial multivalued dependency in the table is a dependency on a superkey |
| 5NF | Fifth normal form | Ronald Fagin | 1979 [13] | Every non-trivial join dependency in the table is implied by the superkeys of the table |
| DKNF | Domain/key normal form | Ronald Fagin | 1981 [14] | Every constraint on the table is a logical consequence of the table's domain constraints and key constraints |
| 6NF | Sixth normal form | C.J. Date, Hugh Darwen, and Nikos Lorentzos | 2002 [15] | Table features no non-trivial join dependencies at all (with reference to generalized join operator) |
SQL Commands:
Refer http://beginner-sql-tutorial.com for all DDL,DML and DCL commands.
Analytical process involves analysis of accumulated data, frequently by end users
Analytical Processing includes datamining, DSSs, EISs, Webapplications,querying and other end user activities.
Datawarehouse is a repository of data that are organized to be readiliy acceptable for analytical processing actvities such as Datamining, Decision Support, Querying & Other Applications.
Eg: Revenue Mgmt, CRM,fraud detection, payroll mgmt.
Enterprise D/Ws:
Marketing and Sales,Customer and Channel partner, Pricing & Contracts,Forecasting,Sales Performance, Financial, Supply Chains, Customer Service Improvement & Order Enforcement, Info mation Systems & Process.
Data is processed in a D/W using a seperate software called ETL(Extract, Transform & Load) S/Ware.
Characteristics of a D/W:
Design of a D/W:
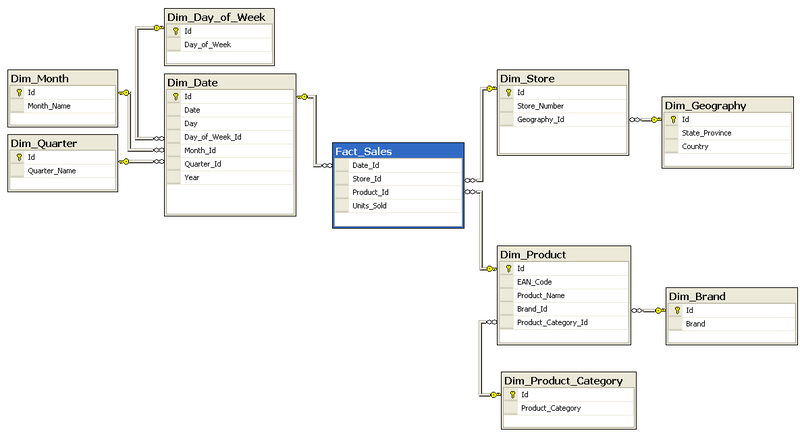
What is a data cube?
It allows data to be modeled and viewed in multiple dimensions.It is defined by dimensions & facts.
Dimensions are the perspectives or entities w.r.t which organization wants to keep records.
Eg: time,item,branch & location
Each dimension will have a table associated with it called Dimension Table.
Facts are numerical measures.This is called as a theme.
The Fact table contains the names of the facts or measures, as well as keys to each of the related dimension tables.
Data Models:
The most popular data model for a D/W is multidimensional model.Such a model can exist in the form of a
 Snow flake Schema
Snow flake Schema
- Organization i.e. subject oriented
- Consistency
- Time Variant
- Non Volatile
- Relational
- Client/Server
- Web based
- Integrated from various sources
- Real time.
Data in a D/W is stored in a multidimensional format especially in the form of data cubes.There are two models namely Snowflake Schema and Star Schema.Another model is also present which is called as Fact Constellation.
Design of a D/W:
- Choosing the subject matter
- Deciding what fact table represents
- Identifying and confirming the dimensions
- Choosing the facts
- Storing pre-calculations in fact table
- Rounding out the dimension tables.
- Choosing the duration of the database
- The need to track slowly changing dimensions
- Deciding the query priorities and query modes
D/W architecture Components:
Multidimensional Model Model- Data Sourcing,Cleaning,transformation, and migration tools
- Metadata repository
- Warehouse database technology
- Data marts
- Data query, reporting, analysis and mining tools
- D/W administration and Management
- Information Delivery System
What is a data cube?
It allows data to be modeled and viewed in multiple dimensions.It is defined by dimensions & facts.
Dimensions are the perspectives or entities w.r.t which organization wants to keep records.
Eg: time,item,branch & location
Each dimension will have a table associated with it called Dimension Table.
Facts are numerical measures.This is called as a theme.
The Fact table contains the names of the facts or measures, as well as keys to each of the related dimension tables.
Data Models:
The most popular data model for a D/W is multidimensional model.Such a model can exist in the form of a
- Star Schema
- Snowflake schema
- Fact Constellation
Star Schema
In data warehousing and business intelligence (BI), a star schema is the simplest form of a dimensional model, in which data is organized into facts and dimensions. A fact is an event that is counted or measured, such as a sale or login. A dimension contains reference information about the fact, such as date, product, or customer. A star schema is diagramed by surrounding each fact with its associated dimensions. The resulting diagram resembles a star.
Star schemas are optimized for querying large data sets and are used in data warehouses and data marts to support OLAP cubes, business intelligence and analytic applications, andad hoc queries.
Within the data warehouse or data mart, a dimension table is associated with a fact table by using a foreign key relationship. The dimension table has a single primary key that uniquely identifies each member record (row). The fact table contains the primary key of each associated dimension table as a foreign key. Combined, these foreign keys form a multi-part composite primary key that uniquely identifies each member record in the fact table. The fact table also contains one or more numeric measures.
For example, a simple Sales fact with millions of individual clothing sale records might contain a Product Key, Promotion Key, Customer Key, and Date Key, along with Units Sold and Revenue measures. The Product dimension would hold reference information such as product name, description, size, and color. The Promotion dimension would hold information such as promotion name and price. The Customer dimension would hold information such as first and last name, birth date, gender, address, etc. The Date dimension would include calendar date, week of year, month, quarter, year, etc. This simple Sales fact will easily support queries such as “total revenue for all clothing products sold during the first quarter of the 2010” or “count of female customers who purchased 5 or more dresses in December 2009”.
The star schema supports rapid aggregations (such as count, sum, and average) of many fact records, and these aggregations can be easily filtered and grouped (“sliced & diced”) by the dimensions. A star schema may be partially normalized (snowflaked), with related information stored in multiple related dimension tables, to support specific data warehousing needs.
Online analytical processing (OLAP) databases (data warehouses and data marts) use a denormalized star schema, with different but related information stored in one dimension table, to optimize queries against large data sets. A star schema may be partially normalized, with related information stored in multiple related dimension tables, to support specific data warehousing needs. In contrast, an online transaction processing (OLTP) database uses a normalized schema, with different but related information stored in separate, related tables to ensure transaction integrity and optimize processing of individual transactions.
In data warehousing, snowflaking is a form of dimensional modeling in which dimensions are stored in multiple related dimension tables. A snowflake schema is a variation of thestar schema.
Snowflaking is used to improve the performance of certain queries. The schema is diagramed with each fact surrounded by its associated dimensions (as in a star schema), and those dimensions are further related to other dimensions, branching out into a snowflake pattern.
Data warehouses and data marts may use snowflaking to support specific query needs. Snowflaking can improve query performance against low cardinality attributes that are queried independently. Business intelligence applications that use a relational OLAP (ROLAP) architecture may perform better when the data warehouse schema is snowflaked.
A star schema stores all attributes for a dimension into one denormalized (“flattened”) table. This requires more disk space than a more normalized snowflake schema. Snowflaking normalizes the dimension by moving attributes with low cardinality (few distinct values) into separate dimension tables that relate to the core dimension table by using foreign keys. Snowflaking for the sole purpose of minimizing disk space is not recommended, however, because it can adversely impact query performance.
Cases for snowflaking include:
- Sparsely populated attributes, where most dimension member records have a NULL value for the attribute, are moved to a sub-dimension.
- Low cardinality attributes that are queried independently. For example, a product dimension may contain thousands of products, but only a handful of product types. Moving the product type attribute to its own dimension table can improve performance when the product types are queried independently.
- Attributes that are part of a hierarchy and are queried independently. Examples include the year, quarter, and month attributes of a date hierarchy; and the country and state attributes of a geographic hierarchy.
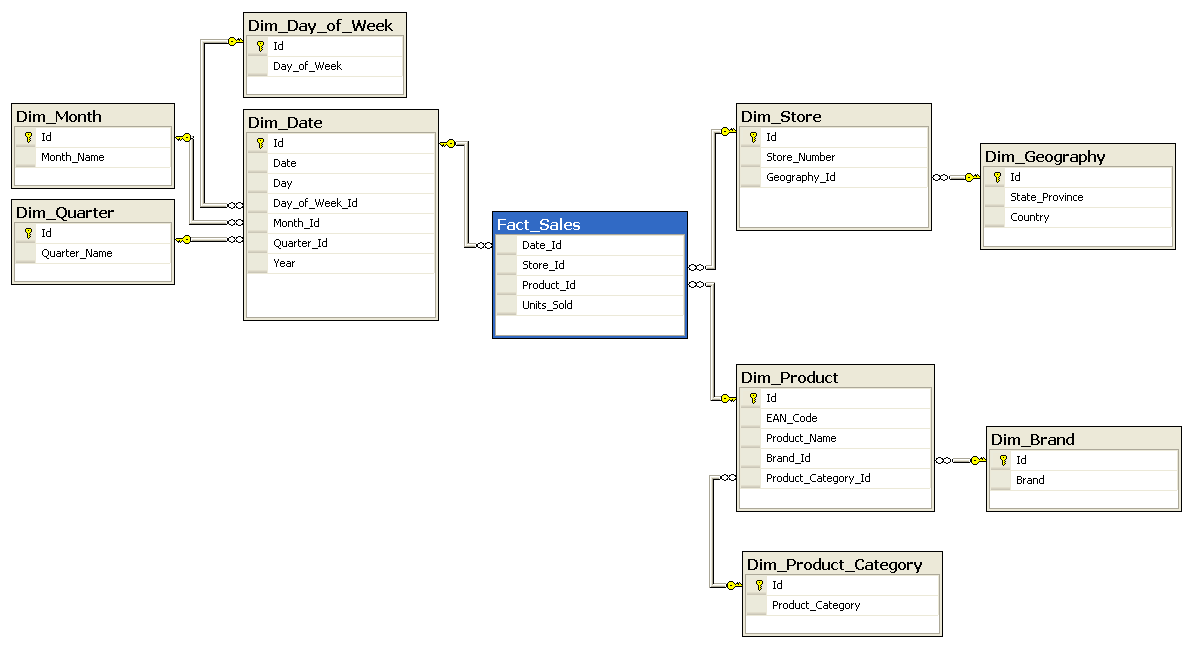
Fact Constellation Schema
What is fact constellation schema? For each star schema it is possible to construct fact constellation schema(for example by splitting the original star schema into more star schemes each of them describes facts on another level of dimension hierarchies). The fact constellation architecture contains multiple fact tables that share many dimension tables.

One way to categorize the different types of computer network designs is by their scope or scale. For historical reasons, the networking industry refers to nearly every type of design as some kind of area network. Common examples of area network types are:
Residences typically employ one LAN and connect to the Internet WAN via an Internet Service Provider (ISP) using a broadband modem. The ISP provides a WAN IP address to the modem, and all of the computers on the home network use LAN (so-called private) IP addresses. All computers on the home LAN can communicate directly with each other but must go through a central gateway, typically abroadband router, to reach the ISP.
TOPOLOGIES

What is fact constellation schema? For each star schema it is possible to construct fact constellation schema(for example by splitting the original star schema into more star schemes each of them describes facts on another level of dimension hierarchies). The fact constellation architecture contains multiple fact tables that share many dimension tables.
Introduction to Network Types
LAN, WAN and Other Area Networks
One way to categorize the different types of computer network designs is by their scope or scale. For historical reasons, the networking industry refers to nearly every type of design as some kind of area network. Common examples of area network types are:
- LAN - Local Area Network
- WLAN - Wireless Local Area Network
- WAN - Wide Area Network
- MAN - Metropolitan Area Network
- SAN - Storage Area Network, System Area Network, Server Area Network, or sometimes Small Area Network
- CAN - Campus Area Network, Controller Area Network, or sometimes Cluster Area Network
- PAN - Personal Area Network
- DAN - Desk Area Network
Note that these network types are a separate concept from network topologies such as bus, ring and star.
LAN - Local Area Network
A LAN connects network devices over a relatively short distance. A networked office building, school, or home usually contains a single LAN, though sometimes one building will contain a few small LANs (perhaps one per room), and occasionally a LAN will span a group of nearby buildings. In TCP/IPnetworking, a LAN is often but not always implemented as a single IP subnet.
In addition to operating in a limited space, LANs are also typically owned, controlled, and managed by a single person or organization. They also tend to use certain connectivity technologies, primarily Ethernet and Token Ring.
WAN - Wide Area Network
As the term implies, a WAN spans a large physical distance. The Internet is the largest WAN, spanning the Earth.
A WAN is a geographically-dispersed collection of LANs. A network device called a routerconnects LANs to a WAN. In IP networking, the router maintains both a LAN address and a WAN address.
A WAN differs from a LAN in several important ways. Most WANs (like the Internet) are not owned by any one organization but rather exist under collective or distributed ownership and management. WANs tend to use technology like ATM, Frame Relay and X.25 for connectivity over the longer distances.
LAN, WAN and Home Networking
Residences typically employ one LAN and connect to the Internet WAN via an Internet Service Provider (ISP) using a broadband modem. The ISP provides a WAN IP address to the modem, and all of the computers on the home network use LAN (so-called private) IP addresses. All computers on the home LAN can communicate directly with each other but must go through a central gateway, typically abroadband router, to reach the ISP.
Other Types of Area Networks
While LAN and WAN are by far the most popular network types mentioned, you may also commonly see references to these others:- Wireless Local Area Network - a LAN based on WiFi wireless network technology
- Metropolitan Area Network - a network spanning a physical area larger than a LAN but smaller than a WAN, such as a city. A MAN is typically owned an operated by a single entity such as a government body or large corporation.
- Campus Area Network - a network spanning multiple LANs but smaller than a MAN, such as on a university or local business campus.
- Storage Area Network - connects servers to data storage devices through a technology like Fibre Channel.
- System Area Network - links high-performance computers with high-speed connections in a cluster configuration. Also known as Cluster Area Network.
TOPOLOGIES
What is a network topology? In communication networks, a topology is a usually schematic description of the arrangement of a network, including its nodes and connecting lines. There are two ways of defining network geometry: the physical topology and the logical (or signal) topology.
The physical topology of a network is the actual geometric layout of workstations. There are several common physical topologies, as described below and as shown in the illustration.
In the bus network topology, every workstation is connected to a main cable called the bus. Therefore, in effect, each workstation is directly connected to every other workstation in the network.
In the star network topology, there is a central computer or server to which all the workstations are directly connected. Every workstation is indirectly connected to every other through the central computer.
In the ring network topology, the workstations are connected in a closed loop configuration. Adjacent pairs of workstations are directly connected. Other pairs of workstations are indirectly connected, the data passing through one or more intermediate nodes.
If a Token Ring protocol is used in a star or ring topology, the signal travels in only one direction, carried by a so-called token from node to node.
The mesh network topology employs either of two schemes, called full mesh and partial mesh. In the full mesh topology, each workstation is connected directly to each of the others. In the partial mesh topology, some workstations are connected to all the others, and some are connected only to those other nodes with which they exchange the most data.
The tree network topology uses two or more star networks connected together. The central computers of the star networks are connected to a main bus. Thus, a tree network is a bus network of star networks.
Logical (or signal) topology refers to the nature of the paths the signals follow from node to node. In many instances, the logical topology is the same as the physical topology. But this is not always the case. For example, some networks are physically laid out in a star configuration, but they operate logically as bus or ring networks.
Electronic business
Electronic commerce, commonly known as e-commerce, is a type of industry where buying and selling of product or service is conducted over electronic systems such as the Internet and other computer networks. Electronic commerce draws on technologies such as mobile commerce,electronic funds transfer, supply chain management, Internet marketing, online transaction processing, electronic data interchange (EDI), inventory management systems, and automated data collection systems. Modern electronic commerce typically uses the World Wide Web at least at one point in the transaction's life-cycle, although it may encompass a wider range of technologies such as e-mail, mobile devices social media, and telephones as well.
Electronic commerce is generally considered to be the sales aspect of e-business. It also consists of the exchange of data to facilitate the financing and payment aspects of business transactions.
E-commerce can be divided into:
- E-tailing or "virtual storefronts" on websites with online catalogs, sometimes gathered into a "virtual mall"
- The gathering and use of demographic data through Web contacts and social media
- Electronic Data Interchange (EDI), the business-to-business exchange of data
- E-mail and fax and their use as media for reaching prospective and established customers (for example, with newsletters)
- Business-to-business buying and selling
- The security of business transactions
Electronic business, commonly referred to as "eBusiness" or "e-business", or an internet business, may be defined as the application of information and communication technologies (ICT) in support of all the activities of business. Commerce constitutes the exchange of products and services between businesses, groups and individuals and can be seen as one of the essential activities of any business. Electronic commerce focuses on the use of ICT to enable the external activities and relationships of the business with individuals, groups and other businesses.[1]
e-business may be defined as the conduct of industry,trade,and commerce using the computer networks.The term "e-business" was coined by IBM's marketing and Internet teams in 1996.[2][3]
Electronic business methods enable companies to link their internal and external data processing systems more efficiently and flexibly, to work more closely with suppliers and partners, and to better satisfy the needs and expectations of their customers. The internet is a public through way. Firms use more private and hence more secure networks for more effective and efficient management of their internal functions.
In practice, e-business is more than just e-commerce. While e-business refers to more strategic focus with an emphasis on the functions that occur using electronic capabilities, e-commerce is a subset of an overall e-business strategy. E-commerce seeks to add revenue streams using the World Wide Web or the Internet to build and enhance relationships with clients and partners and to improve efficiency using the Empty Vessel strategy. Often, e-commerce involves the application of knowledge management systems.
E-business involves business processes spanning the entire value chain: electronic purchasing and supply chain management, processing orders electronically, handling customer service, and cooperating with business partners. Special technical standards for e-business facilitate the exchange of data between companies. E-business software solutions allow the integration of intra and inter firm business processes. E-business can be conducted using the Web, the Internet, intranets, extranets, or some combination of these.
Basically, electronic commerce (EC) is the process of buying, transferring, or exchanging products, services, and/or information via computer networks, including the internet. EC can also be beneficial from many perspectives including business process, service, learning, collaborative, community. EC is often confused with e-business.
Subsets
Applications can be divided into three categories:
- Internal business systems:
- Enterprise communication and collaboration:
- electronic commerce - business-to-business electronic commerce (B2B) or business-to-consumer electronic commerce (B2C):
[edit]Models
When organizations go online, they have to decide which e-business models best suit their goals.[4] A business model is defined as the organization of product, service and information flows, and the source of revenues and benefits for suppliers and customers. The concept of e-business model is the same but used in the online presence. The following is a list of the currently most adopted e-business models such as:
- E-shops
- E-commerce
- E-procurement
- E-malls
- E-auctions
- Virtual Communities
- Collaboration Platforms
- Third-party Marketplaces
- Value-chain Integrators
- Value-chain Service Providers
- Information Brokerage
- Telecommunication
- Customer relationship
[edit]Classification by provider and consumer
Roughly dividing the world into providers/producers and consumers/clients one can classify e-businesses into the following categories:
- business-to-business (B2B)
- business-to-consumer (B2C)
- business-to-employee (B2E)
- business-to-government (B2G)
- government-to-business (G2B)
- government-to-government (G2G)
- government-to-citizen (G2C)
- consumer-to-consumer (C2C)
- consumer-to-business (C2B)
It is notable that there are comparably less connections pointing "upwards" than "downwards" (few employee/consumer/citizen-to-X models).
[edit]Electronic business security
E-Business systems naturally have greater security risks than traditional business systems, therefore it is important for e-business systems to be fully protected against these risks. A far greater number of people have access to e-businesses through the internet than would have access to a traditional business. Customers, suppliers, employees, and numerous other people use any particular e-business system daily and expect their confidential information to stay secure. Hackers are one of the great threats to the security of e-businesses. Some common security concerns for e-Businesses include keeping business and customer information private and confidential, authenticity of data, and data integrity. Some of the methods of protecting e-business security and keeping information secure include physical security measures as well as data storage, data transmission, anti-virus software, firewalls, and encryption to list a few.[5][6]
[edit]Key security concerns within e-business
[edit]Privacy and confidentiality
Confidentiality is the extent to which businesses makes personal information available to other businesses and individuals.[7] With any business, confidential information must remain secure and only be accessible to the intended recipient. However, this becomes even more difficult when dealing with e-businesses specifically. To keep such information secure means protecting any electronic records and files from unauthorized access, as well as ensuring safe transmission and data storage of such information. Tools such as encryption and firewalls manage this specific concern within e-business.[6]
[edit]Authenticity
E-business transactions pose greater challenges for establishing authenticity due to the ease with which electronic information may be altered and copied. Both parties in an e-business transaction want to have the assurance that the other party is who they claim to be, especially when a customer places an order and then submits a payment electronically. One common way to ensure this is to limit access to a network or trusted parties by using a virtual private network (VPN) technology. The establishment of authenticity is even greater when a combination of techniques are used, and such techniques involve checking "something you know" (i.e. password or PIN), "something you need " (i.e. credit card), or "something you are" (i.e. digital signatures or voice recognition methods). Many times in e-business, however, "something you are" is pretty strongly verified by checking the purchaser's "something you have" (i.e. credit card) and "something you know" (i.e. card number).[6]
[edit]Data integrity
Data integrity answers the question "Can the information be changed or corrupted in any way?" This leads to the assurance that the message received is identical to the message sent. A business needs to be confident that data is not changed in transit, whether deliberately or by accident. To help with data integrity, firewalls protect stored data against unauthorized access, while simply backing up data allows recovery should the data or equipment be damaged.[6]
[edit]Non-repudiation
This concern deals with the existence of proof in a transaction. A business must have assurance that the receiving party or purchaser cannot deny that a transaction has occurred, and this means having sufficient evidence to prove the transaction. One way to address non-repudiation is using digital signatures.[6] A digital signature not only ensures that a message or document has been electronically signed by the person, but since a digital signature can only be created by one person, it also ensures that this person cannot later deny that they provided their signature.[8]
[edit]Access control
When certain electronic resources and information is limited to only a few authorized individuals, a business and its customers must have the assurance that no one else can access the systems or information. Fortunately, there are a variety of techniques to address this concern including firewalls, access privileges, user identification and authentication techniques (such as passwords and digital certificates), Virtual Private Networks (VPN), and much more.[6]
[edit]Availability
This concern is specifically pertinent to a business' customers as certain information must be available when customers need it. Messages must be delivered in a reliable and timely fashion, and information must be stored and retrieved as required. Because availability of service is important for all e-business websites, steps must be taken to prevent disruption of service by events such as power outages and damage to physical infrastructure. Examples to address this include data backup, fire-suppression systems, Uninterrupted Power Supply (UPS) systems, virus protection, as well as making sure that there is sufficient capacity to handle the demands posed by heavy network traffic.[6]
[edit]Common security measures
Many different forms of security exist for e-businesses. Some general security guidelines include areas in physical security, data storage, data transmission, application development, and system administration.
[edit]Physical security
Despite e-business being business done online, there are still physical security measures that can be taken to protect the business as a whole. Even though business is done online, the building that houses the servers and computers must be protected and have limited access to employees and other persons. For example, this room should only allow authorized users to enter, and should ensure that "windows, dropped ceilings, large air ducts, and raised floors" do not allow easy access to unauthorized persons.[5] Preferably these important items would be kept in an air-conditioned room without any windows.[9]
Protecting against the environment is equally important in physical security as protecting against unauthorized users. The room may protect the equipment against flooding by keeping all equipment raised off of the floor. In addition, the room should contain a fire extinguisher in case of fire. The organization should have a fire plan in case this situation arises.[5]
In addition to keeping the servers and computers safe, physical security of confidential information is important. This includes client information such as credit card numbers, checks, phone numbers, etc. It also includes any of the organization's private information. Locking physical and electronic copies of this data in a drawer or cabinet is one additional measure of security. Doors and windows leading into this area should also be securely locked. Only employees that need to use this information as part of their job should be given keys.[5]
Important information can also be kept secure by keeping backups of files and updating them on a regular basis. It is best to keep these backups in a separate secure location in case there is a natural disaster or breach of security at the main location.[5]
"Failover sites" can be built in case there is a problem with the main location. This site should be just like the main location in terms of hardware, software, and security features. This site can be used in case of fire or natural disaster at the original site. It is also important to test the "failover site" to ensure it will actually work if the need arises.[9]
State of the art security systems, such as the one used at Tidepoint's headquarters, might include access control, alarm systems, and closed-circuit television. One form of access control is face (or another feature) recognition systems. This allows only authorized personnel to enter, and also serves the purpose of convenience for employees who don't have to carry keys or cards. Cameras can also be placed throughout the building and at all points of entry. Alarm systems also serve as an added measure of protection against theft.[10]
Thanks for sharing your valuable information about the generation of computers in a brief. Want to know more about IT Services Dubai
ReplyDeleteVery informative post Dr Narendra Kumar The explanation of computer generations is clear and easy to understand It is fascinating to see how technology evolved from vacuum tubes to transistors and beyond Just like advancements in IT have transformed our daily lives platforms like eauctions are transforming transparency and efficiency in business processes Your content is very helpful for learners and professionals alike
ReplyDelete